centos 运行yum makecache生成缓存有时候会出现这个问题,
Not using downloaded repomd.xml because it is older than what we have
解决方法:清空/var/cache/yum/目录下面的文件
rm -rf /var/cache/yum/*
centos 运行yum makecache生成缓存有时候会出现这个问题,
Not using downloaded repomd.xml because it is older than what we have
解决方法:清空/var/cache/yum/目录下面的文件
rm -rf /var/cache/yum/*
centos 运行yum makecache生成缓存有时候会出现这个问题,
Not using downloaded repomd.xml because it is older than what we have
解决方法:清空/var/cache/yum/目录下面的文件
rm -rf /var/cache/yum/*
Keepalived-Redis(主从高可用)方案
当系统中只有一台redis运行时,一旦该redis挂了,会导致整个系统无法运行,所以想到的办法自然就是备份。一台redis出现问题了,另一台redis可以继续提供服务。但由于redis目前只支持主从复制备份(不支持主主复制),当主redis挂了,从redis只能提供读服务,无法提供写服务。所以,还得想办法,当主redis挂了,我们让从redis升级成为主redis。这就需要自动故障转移,keepalived可以实现redis的双机热备作为过渡方案。
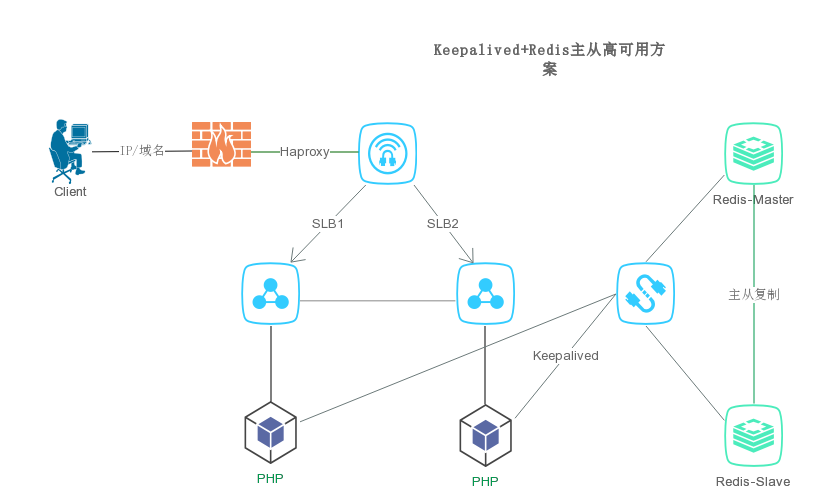
环境说明:
操作系统:CentOS release 6.8 (64)
Master IP:192.168.129.132
Slave IP:192.168.129.133
Virtural IP : 192.168.129.100
Redis Version: 3.2.28
Keepalived v1.2.13
前期准备:
1、下载包到/usr/local/src目录,配置yum源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
yum makecahce
yum install -y gcc openssl-devel kernel-devel 2、修改Hostname主机名,关闭selinux和iptables
[root@localhost ~]# sed -i 's@SELINUX=enforcing@SELINUX=disabled@g' /etc/selinux/config
[root@localhost ~]# setenforce 0
[root@localhost ~]# /etc/init.d/iptables stop 3、分别修改两台主机名为redis_master 和 redis_slave
[root@localhost ~]# vim /etc/sysconfig/network
HOSTNAME=redis_master
[root@localhost ~]# vim /etc/sysconfig/network
HOSTNAME=redis_slave 4、禁用大内存页面,详细请了解此篇文章
http://blog.csdn.net/longwang155069/article/details/50897026
[root@redis_master ~]# echo 'never' > /sys/kernel/mm/transparent_hugepage/enabled
[root@redis_master ~]# vi /etc/sysctl.conf #编辑,在最后一行添加下面代码
vm.overcommit_memory = 1
[root@redis_master ~]# sysctl -p #使设置立即生效
Redis主从搭建
详细步骤
#下载Redis,两台机器都需要做相同操作
[root@redis_master ~]# wget http://download.redis.io/releases/redis-3.2.8.tar.gz
#解压
[root@redis_master ~]# tar -zxvf redis-3.2.8.tar.gz
[root@redis_master ~]# cd redis-3.2.8
[root@redis_master ~]# make
[root@redis_master ~]# make install PREFIX=/usr/local/redis
mkdir /usr/local/redis/etc #下载配置文件和启动脚本
wget http://soft.8090st.com/conf/redis.conf -O /usr/local/redis/etc/redis.conf
wget http://soft.8090st.com/shell/redis.sh -O /etc/init.d/redis
#添加redis用户
useradd -s /sbin/nologin redis
mkdir /usr/local/redis/var
chmod 777 /usr/local/redis/var
chmod 755 /etc/init.d/redis
chkconfig --add redis
chkconfig redis on
#启动redis测试是否正常
service redis start

#redis主从配置文件
①、主redis需要修改的文件及内容
[root@redis_master ~]# vi /usr/local/redis/etc/redis.conf
bind 0.0.0.0其余都可以安装默认状态
②、从redis需要修改的文件及内容
[root@redis_slave ~]# vi /usr/local/redis/etc/redis.conf
bind 0.0.0.0
slaveof 192.168.129.132 6379 //指定主redis的地址与端口如果master设置了验证密码,还需配置masterauth。如果master设置了验证密码为admin,应当配置masterauth admin。
配置完之后重新启动slave的Redis服务,OK,主从配置完成。下面测试一下:
在master和slave分别执行info命令,查看结果如下:
# 查看主从状态
Redis主
[root@redis_master ~]# redis-cli info |grep role -A 3

Redis从
[root@redis_slave ~]# ../bin/redis-cli info |grep role -A 3

测试现在redis主从是否同步数据
[root@redis_master bin]# redis-cli
127.0.0.1:6379> set a a
OK
在从上get查看a的值,结果和redis主的值相同。
[root@redis_slave bin]# redis-cli
127.0.0.1:6379> get a
"a"
在Redis从服务器上试试能不能插入数据。
redis-cli -p 6379 set hello world
(error) READONLY You can’t write against a read only slave.
成功配置主从redis服务器,由于配置中有一条从服务器是只读的,所以从服务器没法设置数据,只可以读取数据。
安装过程错误解决方法
zmalloc.h:50:31: error: jemalloc/jemalloc.h: No such file or directory
zmalloc.h:55:2: error: #error “Newer version of jemalloc required”
make[1]: *** [adlist.o] Error 1
#make MALLOC=libc
1. 安装和配置keepalived
在Master和Slave上安装Keepalived
这里以yum安装为例
$ yum install -y keepalivedkeepalived安装完成后,我们需要修改它的配置文件:
首先,在Master上创建如下配置文件:
$ mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_bak
$ > /etc/keepalived/keepalived.conf
$ vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id redis100
}
vrrp_script chk_redis
{
script “/etc/keepalived/scripts/redis_check.sh 127.0.0.1 6379”
interval 2
timeout 2
fall 3
}
vrrp_instance redis {
state MASTER # master set to SLAVE also
interface eth0
virtual_router_id 50
priority 150
nopreempt # no seize,must add
advert_int 1
authentication { #all node must same
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.129.100/24 //定义虚拟浮动IP
}
track_script {
chk_redis
}
notify_master “/etc/keepalived/scripts/redis_master.sh 192.168.129.133 6379"
notify_backup “/etc/keepalived/scripts/redis_backup.sh 192.168.129.133 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
//192.168.129.133 定义redis从服务器IP
//interface eth0 定义网卡名称,有的网卡名不相同,请自行修改
然后,在Slave上创建如下配置文件:
! Configuration File for keepalived
global_defs {
router_id redis101
}
vrrp_script chk_redis
{
script “/etc/keepalived/scripts/redis_check.sh 127.0.0.1 6379”
interval 2
timeout 2
fall 3
}
vrrp_instance redis {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication { #all node must same
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.200/24
}
track_script {
chk_redis
}
notify_master “/etc/keepalived/scripts/redis_master.sh 192.168.129.132 6379"
notify_backup “/etc/keepalived/scripts/redis_backup.sh 192.168.129.132 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
//192.168.129.132 定义redis主服务器IP
//interface eth0 定义网卡名称,有的网卡名不相同,请自行修改
在Master和Slave上创建监控Redis的脚本
$ mkdir /etc/keepalived/scripts
$ vim /etc/keepalived/scripts/redis_check.sh
#!/bin/bash
ALIVE=`/usr/local/redis/bin/redis-cli -h $1 -p $2 PING`
LOGFILE="/var/log/keepalived-redis-check.log"
echo "[CHECK]" >> $LOGFILE
date >> $LOGFILE
if [ $ALIVE == "PONG" ]; then :
echo "Success: redis-cli -h $1 -p $2 PING $ALIVE" >> $LOGFILE 2>&1
exit 0
else
echo "Failed:redis-cli -h $1 -p $2 PING $ALIVE " >> $LOGFILE 2>&1
exit 1
fi
编写以下负责运作的关键脚本:
notify_master /etc/keepalived/scripts/redis_master.sh
notify_backup /etc/keepalived/scripts/redis_backup.sh
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
因为Keepalived在转换状态时会依照状态来呼叫:
当进入Master状态时会呼叫notify_master
当进入Backup状态时会呼叫notify_backup
当发现异常情况时进入Fault状态呼叫notify_fault
当Keepalived程序终止时则呼叫notify_stop
首先,在Redis Master上创建notity_master与notify_backup脚本:
$ vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli -h $1 -p $3"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run MASTER cmd ..." >> $LOGFILE 2>&1
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE
sleep 10 #delay 10 s wait data async cancel sync
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
$ vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[backup]" >> $LOGFILE
date >> $LOGFILE
echo "Run SLAVEOF cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE 2>&1
# echo "Being slave...." >> $LOGFILE 2>&1
sleep 15 #delay 15 s wait data sync exchange role
接着,在Redis Slave上创建notity_master与notify_backup脚本:
$ vim /etc/keepalived/scripts/redis_master.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli -h $1 -p $3"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[master]" >> $LOGFILE
date >> $LOGFILE
echo "Being master...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ... " >> $LOGFILE
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE 2>&1
#echo "SLAVEOF $2 cmd can't excute ... " >> $LOGFILE
sleep 10 ##delay 15 s wait data sync exchange role
echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE
$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2>&1
$ vim /etc/keepalived/scripts/redis_backup.sh
#!/bin/bash
REDISCLI="/usr/local/redis/bin/redis-cli"
LOGFILE="/var/log/keepalived-redis-state.log"
echo "[BACKUP]" >> $LOGFILE
date >> $LOGFILE
echo "Being slave...." >> $LOGFILE 2>&1
echo "Run SLAVEOF cmd ..." >> $LOGFILE 2>&1
$REDISCLI SLAVEOF $2 $3 >> $LOGFILE
sleep 100 #delay 10 s wait data async cancel sync
exit(0)
然后在Master与Slave创建如下相同的脚本:
$ vim /etc/keepalived/scripts/redis_fault.sh
#!/bin/bash
LOGFILE=/var/log/keepalived-redis-state.log
echo "[fault]" >> $LOGFILE
date >> $LOGFILE
$ vim /etc/keepalived/scripts/redis_stop.sh
#!/bin/bash
LOGFILE=/var/log/keepalived-redis-state.log
echo "[stop]" >> $LOGFILE
date >> $LOGFILE
给脚本都加上可执行权限:
(这点很重要,最开始由于这不没做,运行后一直报错 “VRRP_Instance(Redis) Now in FAULT state”)
$ chmod +x /etc/keepalived/scripts/*.sh
脚本创建完成以后,我们开始按照如下流程进行测试:
1.启动Master上的Redis
[root@redis_master ~]# /etc/init.d/redis start
Starting redis-server: [ OK ]
2.启动Slave上的Redis
[root@redis_slave ~]# /etc/init.d/redis start
Starting redis-server: [ OK ]
3.启动Master上的Keepalived
[root@redis_master ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
启动后我们看下eth0这张网卡是否有VIP
[root@redis_master ~]# ip a

4.启动Slave上的Keepalived
[root@redis_slave ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
5.客户机尝试通过VIP连接Redis:
[root@localhost ~]# redis-cli -h 192.168.129.100 INFO |grep role -A 3

从图中我们可以看出当前从机器是192.168.129.133
6.尝试插入一些数据:
$ redis-cli -h 192.168.129.100 SET Hello Redis

从VIP读取数据
$ redis-cli -h 192.168.129.100 GET Hello

从Master读取数据
$ redis-cli -h 192.168.129.132 GET Hello
![]()
从Slave读取数据
$ redis-cli -h 192.168.129.133 GET Hello
![]()
接下来模拟故障产生:
将Master上的Redis停了
$ service redis stop
查看Master上的Keepalived日志
$ tailf /var/log/keepalived-redis-state.log
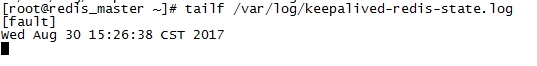
同时Slave上的日志显示:
$ tailf /var/log/keepalived-redis-state.log
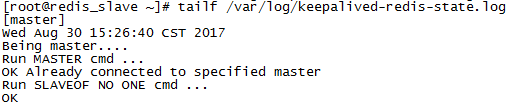
然后我们可以发现,Slave已经接管服务,并且担任Master的角色了。
$ redis-cli -h 192.168.129.100 INFO
然后我们恢复Master的Redis进程
$ service redis start
查看Master上的Keepalived日志
$ tailf /var/log/keepalived-redis-state.log
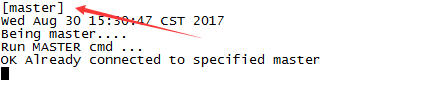
同时Slave上的日志显示:
$ tailf /var/log/keepalived-redis-state.log

可以发现目前的Master已经再次恢复了Master的角色,故障切换以及自动恢复都成功了。
注意事项:主从的redis都要开启持续化本地备份,否则数据会丢失。
1.master slave IP、VIP位于同一个vlan
2. interface 网卡名称配置正确
3. virtual_router_id VRRP 的Id 不能与vlan 其他设备使用的冲突
4.配置2s检测一次,3次都失败才认为要切换
Q: 当在另一台机器上登录MySQL时出现如下错误:
ERROR 2003 (HY000): Can't connect to MySQL server on 'x.x.x.x' (111)A: 原因是MySQL考虑到安全因素,默认配置只让从本地登录
打开 /etc/mysql/my.cnf 文件,找到 bind-address = 127.0.0.1 修改为 bind-address = 0.0.0.0
重启mysql : sudo /etc/init.d/mysql restart
可参考:
> I've already check my /etc/my.cnf file for a "binding"
> line. Its not
> there. I also found an item online that indicated
> adding:
>
Look for the option "skip-networking". This disables TCP/IP so the
server only accepts local connections via the Unix socket. This sounds1
like your situation.
Note that a "could not connect" error means just that. If the problem
was related to user privileges you would get an "access denied" error.Q: 还一种情况出现类似下面的错误:
ERROR 1045 (28000): Access denied for user 'test'@'x.x.x.x' (using password: NO)A: 原因是没有给登录用户名设置远程主机登录的权限。
在本地用 root 登录: mysql -u root -p
修改 MySQL 数据库中 user 表中 对应用户名的 Host 字段,将 localhost 改为 %
use mysql;
update user set Host = '%' where User = 'username'; HA即(high available)高可用,又被叫做双机热备,用于关键性业务。 工作原理:heartbeat最核心的包括两个部分,心跳监测部分和资源接管部分,心跳监测可以通过网络链路和串口进行,而且支持冗 余链路,它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运 行在对方主机上的资源或者服务。常见的实现高可用的开源软件有 heartbeat 和 keepalived。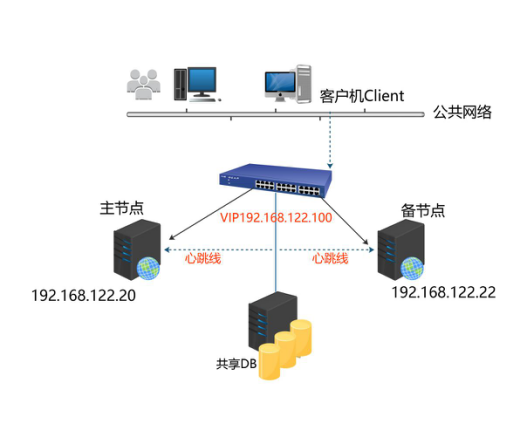
前期准备:
1、修改Hostname主机名 (2台节点都需要操作)
[root@web1 ~]# vim /etc/sysconfig/network2、增加hosts (2台节点都需要操作)
[root@web1 ~]# vim /etc/hosts#增加内容如下:
192.168.122.20 web1
192.168.122.22 web2
3、关闭iptables和selinux。(2台节点都需要操作)
[root@web1 ~]# service iptables stop[root@web1 ~]# setenforce 0[root@web1 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config4、双机所需软件: libnet heartbeat nginx
#安装扩展源,或者使用阿里云扩展http://mirrors.aliyun.com/help/epel
[root@web1 ~]# yum install epel-relese -y
[root@web1 ~]# yum install –y libnet heartbeat nginx配置heartbeat拷贝配置文件
[root@web1 ~]# cd /usr/share/doc/heartbeat-3.0.4/
[root@web1 heartbeat-3.0.4]# cp ha.cf haresources authkeys /etc/ha.d/
[root@web1 heartbeat-3.0.4]# cd /etc/ha.d/5、修改authkeys #取消注释,认证方式选择md5
[root@web1 ha.d]# vim authkeysauth 3
3 md5 Hello!
[root@web1 ha.d]# chmod 600 authkeys //然后修改其权限
6、编辑haresources文件
[root@web1 ha.d]# vim haresources加入下面一行:
web1 192.168.122.100/eth0 nginx
//说明:web1为主节点hostname,192.168.122.100为vip,/24为掩码为24的网段,eth0为vip的设备名,nginx为heartbeat监控的服务,也是两台机器对外提供的核心服务。
7、编辑ha.cf
[root@web1 ha.d]# vim ha.cf修改为如下内容:
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 30
warntime 10
initdead 60
udpport 694
ucast eth0 192.168.122.22 //添加备机IP
auto_failback on
node master
node slave
ping 192.168.122.1 //网关IP
respawn hacluster /usr/lib64/heartbeat/ipfail
配置说明:
debugfile /var/log/ha-debug //该文件保存heartbeat的调试信息。
logfile /var/log/ha-log //heartbeat的日志文件。
keepalive 2 //心跳的时间间隔,默认时间单位为秒s。
deadtime 30 //超出该时间间隔未收到对方节点的心跳,则认为对方已经死亡。
warntime 10 //超出该时间间隔未收到对方节点的心跳,则发出警告并记录到日志中。
initdead 60 //系统启动或重启之后需要经过一段时间网络才能正常工作,该选项用于解决这种情况产生的时间间隔,取值至少为deadtime的2倍。
udpport 694 //设置广播通信使用的端口,694为默认使用的端口号。
ucast eth0 192.168.122.22 //设置对方机器心跳检测的网卡和IP。
auto_failback on //heartbeat的两台主机分别为主节点和从节点。主节点在正常情况下占用资源并运行所有的服务,遇到故障时把资源交给从节点由从节点运行服务。在该选项设为on的情况下,一旦主节点恢复运行,则自动获取资源并取代从节点,否则不取代从节点。
respawn heartbeat /usr/lib64/heartbeat/ipfail
指定与heartbeat一同启动和关闭的进程,该进程被自动监视,遇到故障则重新启动。最常用的进程是ipfail,该进程用于检测和处理网络故障,需要配合ping语句指定的ping node来检测网络连接。如果你的系统是64bit,请注意该文件的路径。
8、把主节点上的三个配置文件拷贝到从节点
[root@web1 ha.d]# scp authkeys ha.cf haresources web2:/etc/ha.d#如找不到scp命令,请yum 安装openssh-clients
9、从节点slave编辑ha.cf
[root@web2 ~]# vim /etc/ha.d/ha.cf只需要更改一个地方如下:
ucast eth0 192.168.122.22改为ucast eth0 192.168.122.20 //改为主机器IP
10、启动heartbeat服务
配置完毕后,先master启动,后slave启动。
[root@web1 ~]# service heartbeat startStarting High-Availability services: INFO: Resource is stopped
Done.
11、检查测试
[root@web1 ha.d]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:90:ee:8d brd ff:ff:ff:ff:ff:ff
inet 192.168.122.20/24 brd 192.168.122.255 scope global eth0
inet 192.168.122.120/24 brd 192.168.122.255 scope global secondary eth0
//浮动IP已漂移到主上面192.168.122.120
[root@web1 ha.d]# ps aux |grep nginx
root 15062 0.0 0.4 108936 2172 ? Ss 03:09 0:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 15064 0.0 0.6 109360 3204 ? S 03:09 0:00 nginx: worker process
[root@web1 ha.d]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 17545/nginx
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2082/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1345/master
tcp 0 0 :::80 :::* LISTEN 17545/nginx
tcp 0 0 :::22 :::* LISTEN 2082/sshd
tcp 0 0 ::1:25 :::* LISTEN 1345/master
在从节点启动heartbeat
[root@web2 ~]# service heartbeat start
[root@web2 ~]# ip a2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:e3:92:b7 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.22/24 brd 192.168.122.255 scope global eth0
inet6 fe80::5054:ff:fee3:92b7/64 scope link
valid_lft forever preferred_lft forever
此时从节点没有浮动IP
12、测试方式
(1)主节点上禁ping看浮动IP是否漂移到从节点
[root@web1 ~]# iptables -I INPUT -p icmp -j DROP
[root@web1 ~]# /etc/init.d/heartbeat stop #主节点停止heartbeat服务
[root@web2 ha.d]# tailf /var/log/ha-debug #观察从节点ha-debug日志
Jul 26 05:26:06 web3 ipfail: [6977]: debug: Got asked for num_ping.
Jul 26 05:26:06 web3 ipfail: [6977]: debug: Found ping node 192.168.122.1!
Jul 26 05:26:07 web3 ipfail: [6977]: info: Ping node count is balanced.
Jul 26 05:26:07 web3 ipfail: [6977]: debug: Abort message sent.
Jul 26 05:26:08 web3 heartbeat: [6949]: info: local resource transition completed.
Jul 26 05:26:08 web3 heartbeat: [6949]: info: Initial resource acquisition complete (T_RESOURCES(us))
Jul 26 05:26:08 web3 heartbeat: [7002]: info: No local resources [/usr/share/heartbeat/ResourceManager listkeys web3] to acquire.
Jul 26 05:26:09 web3 heartbeat: [6949]: info: remote resource transition completed.
Jul 26 05:26:09 web3 ipfail: [6977]: debug: Other side is unstable.
Jul 26 05:26:09 web3 ipfail: [6977]: debug: Other side is now stable.
Jul 26 05:46:27 web3 ipfail: [6977]: debug: Got asked for num_ping.
Jul 26 05:46:27 web3 ipfail: [6977]: debug: Found ping node 192.168.122.1!
Jul 26 05:46:28 web3 ipfail: [6977]: info: Telling other node that we have more visible ping nodes.
Jul 26 05:46:28 web3 ipfail: [6977]: debug: Sending you_are_dead.
Jul 26 05:46:28 web3 ipfail: [6977]: debug: Message [you_are_dead] sent.
Jul 26 05:46:34 web3 heartbeat: [6949]: info: web1 wants to go standby [all]
Jul 26 05:46:34 web3 ipfail: [6977]: debug: Other side is unstable.
Jul 26 05:46:35 web3 heartbeat: [6949]: info: standby: acquire [all] resources from web1
Jul 26 05:46:35 web3 heartbeat: [7117]: info: acquire all HA resources (standby).
ResourceManager(default)[7130]: 2017/07/26_05:46:35 info: Acquiring resource group: web1 192.168.122.120/24/eth0 nginx
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_192.168.122.120)[7158]: 2017/07/26_05:46:35 INFO: Resource is stopped
ResourceManager(default)[7130]: 2017/07/26_05:46:35 info: Running /etc/ha.d/resource.d/IPaddr 192.168.122.120/24/eth0 start
IPaddr(IPaddr_192.168.122.120)[7285]: 2017/07/26_05:46:35 INFO: Adding inet address 192.168.122.120/24 with broadcast address 192.168.122.255 to device eth0
IPaddr(IPaddr_192.168.122.120)[7285]: 2017/07/26_05:46:35 INFO: Bringing device eth0 up
IPaddr(IPaddr_192.168.122.120)[7285]: 2017/07/26_05:46:35 INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-192.168.122.120 eth0 192.168.122.120 auto not_used not_used
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_192.168.122.120)[7259]: 2017/07/26_05:46:35 INFO: Success
INFO: Success
ResourceManager(default)[7130]: 2017/07/26_05:46:35 info: Running /etc/init.d/nginx start
Starting nginx: [ OK ]
Jul 26 05:46:35 web3 heartbeat: [7117]: info: all HA resource acquisition completed (standby).
Jul 26 05:46:35 web3 heartbeat: [6949]: info: Standby resource acquisition done [all].
Jul 26 05:46:35 web3 heartbeat: [6949]: info: remote resource transition completed.
Jul 26 05:46:35 web3 ipfail: [6977]: debug: Other side is now stable.
Jul 26 05:46:35 web3 ipfail: [6977]: debug: Other side is now stable.
ARPING 192.168.122.120 from 192.168.122.120 eth0
Sent 5 probes (5 broadcast(s))
Received 0 response(s)
查看从节点是否有浮动IP, Nginx进程是否启动成功
[root@web2 ~]# ip a2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:e3:92:b7 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.22/24 brd 192.168.122.255 scope global eth0
inet 192.168.122.120/24 brd 192.168.122.255 scope global secondary eth0
[root@web3 ~]# netstat -lntp
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 8050/nginx
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1685/master[root@mysql-proxy ~]# curl 192.168.122.120 //客户端测试机器
Web3(2)测试脑裂
主节点master和从节点slave都down掉eth1网卡
[root@web1 ~]# ifdown eth1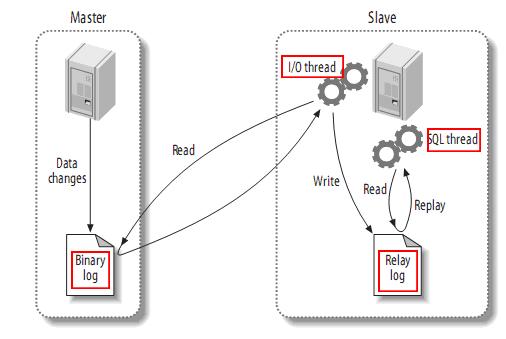
搭建主从,必须保证主从数据库数据一致。 [root@master ~]# vim /etc/sysconfig/network
[root@master ~]# vim /etc/hosts
[root@master ~]# cd /usr/local/src[root@master ~]# wget https://mirrors.tuna.tsinghua.edu.cn/mysql/downloads/MySQL-5.6/mysql-5.6.35-linux-glibc2.5-x86_64.tar.gz [root@master ~]# tar –zxvf mysql-5.6.35-linux-glibc2.5-x86_64.tar.gz [root@master ~]# mv mysql-5.6.35-linux-glibc2.5-x86_64 /usr/local/mysql [root@master ~]# useradd -s /sbin/nologin mysql -M [root@master ~]# cd /usr/local/mysql
[root@master ~]# mkdir -p /data/mysql ; chown -R mysql.mysql /data/mysql
[root@master ~]# ./scripts/mysql_install_db --user=mysql --datadir=/data/mysql/ [root@master ~]# cp support-files/my-default.cnf /etc/my.cnf [root@master ~]# cp support-files/mysql.server /etc/init.d/mysql
[root@master ~]# chmod 755 !$ [root@master ~]# vim /etc/init.d/mysql
Datadir=
Basedir=
[root@master ~]# chkconfig --add mysql
[root@master ~]# chkconfig mysql on [root@master ~]# service mysql start
Stating MySQL. SUCCESS! [root@master ~]# vim /etc/profile.d/mysql.sh
export PATH=$PATH:/usr/local/mysql/bin [root@master ~]# source !$ [root@master ~]# netstat -lntp |grep 3306
tcp 0 0 :::3306 :::* LISTEN 2057/mysqld [root@master ~]# vim /usr/local/mysql/my.cnf server-id=1
log-bin=mysql-bin
binlog-do-db=databasename1,databasename2
binlog-ignore-db=databasename1,databasename2
[root@master ~]# mysqladmin -uroot password ‘123456'
[root@master ~]# mysql -uroot -p123456
mysql> grant replication slave on *.* to 'slave'@'192.168.120.11' identified by 'hello123';
mysql> flush privileges; //刷新权限 [root@master ~]# service mysql restart //重启服务
mysql> flush tables with read lock; //锁定数据库,此时不允许更改任何数据
mysql> show master status; //查看状态,这些数据是要记录的,一会要在slave端用到
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000006 | 474952 | | |
+------------------+----------+--------------+------------------+ [root@slave ~]# mysql -uroot -p123456
mysql> stop slave;
mysql> change master to master_host='192.168.120.10', master_port=3306,
master_user='slave', master_password='hello123',
master_log_file='mysql-bin.000006', master_log_pos=474952;
mysql> start slave; Slave_IO_Running: Yes
Slave_SQL_Running: Yes
[root@master ~]# mysql -uroot -p123456 -e "use db1;
truncate table db"
[root@master ~]# mysql -uroot -p123456 -e "use db1;
select count(*) from db"[root@master ~]# mysql -uroot -p123456 -e "use db1; drop table db"
[root@slave ~]# mysql -uroot -pyourpassword -e "use db1; select count(*) from db"
ERROR 1146 (42S02) at line 1: Table 'db1.db' doesn't exist
1、
宋,男。
宋是个粗人。
宋的爱好是:足疗,烫头,蹦迪。
宋的梦想是,开一家足疗店,找一个烫头小妹做女朋友,晚上带她去蹦迪。
然后宋就爱上了文艺女,楠。
2、
宋对楠是一见钟情。
那时宋正在筹备自己的足疗店,他去踩点,地址在大学城街尾,来往人流很多很杂。
宋很满意,走进街头咖啡厅,等着朋友一块去蹦迪。
就在一杯咖啡的时间内,宋喜欢上了坐在玻璃窗旁边的女大学生,楠。
她坐在窗边摆弄着手指,看上去很美。
那天宋一共喝了十二杯咖啡。
喝完第十二杯咖啡之后,宋感觉自己那一颗火辣辣的真心马上就要从裤裆里跳出来了。
宋鼓起勇气去跟楠搭讪说,打扰一下,你在听歌么?
楠笑笑,说,是啊。
宋说,占用一点你听歌的时间,带你出去玩好么?
楠问宋,看电影还是听音乐?
宋说,都不是,咱们去按脚。
3、
宋带楠去学校附近最大的足疗店。
为宋和楠服务的是两个大娘,宋让大娘给楠做个全身,因为要给,就要给楠最好的。
楠让大娘给宋按个头,看看宋是不是脑子坏了。
宋对楠说,我打算开一家足疗店,比这家还大,技术比这家还好,你喜欢么?
楠说,不喜欢。
宋追问,你不喜欢哪里?水不够温么?力道不够足么?还是大娘长得不够好看?
楠说,我不喜欢足疗。
宋问楠,那你喜欢什么?
楠掏出耳机,放到宋耳朵里,问,黑色叛逆摩托俱乐部,你知道么?
宋不知道。
楠不喜欢宋这样的粗人,楠喜欢文艺卦的男生。
楠和宋,压根不是一个世界的人。
4、
一个月后,宋去达达舞厅蹦迪,舞池里,宋看到了楠。
大家蹦迪是为了开心的,可楠一点都不开心。
顺着楠的视线,宋看到了两个人在舞池中央跳着贴面舞。
一个是电影系的长头发学长,那是楠刚分手的前男友。
一个是舞蹈系女生,那是导致他们分手的原因。
他们在参加扭扭舞比赛,获胜者的奖品是三千块的会员卡。
宋拉着他的哥们冲到舞池中央就开始跳舞,在热情又暧昧地展示了机械舞,扭扭舞,贴面舞,踢踏舞之后,底下的观众一致要求让这对小gay得奖。
宋走过长头发学长身边,恶狠狠地说,你和你马子,蹦迪蹦得烂透了!
他本来长的就很凶,寸头,浓眉大眼,额角有疤,长头发学长一点不敢吱声。
宋把赢得的会员卡拍在楠面前,大声说,我知道了!
楠大声问,什么?
宋大喊,“黑色叛逆摩托俱乐部”是他妈一个硬核摇滚乐队!
5、
在约会失败之后的一个月内,宋备足了功课。
永远不要低估一个直男。直男为了追马子,什么都干得出来。
这一个月,宋左耳戴着耳机,看完了豆瓣250部电影。
而宋的右耳献给了音乐,他听完了各种小众音乐,从“左小祖咒”到“黑色叛逆摩托俱乐部”,起码听了3000首摇滚乐,没他妈一首自己喜欢的。
宋感叹,麻痹,老子高考都没有这么努力过。
在这一个月,宋还把自己的店开起来了。
只是店铺不在街尾,在街头,楠就读大学的旁边。
只是店铺不是足疗店,变成了一家咖啡店,是楠喜欢的风格。
咖啡店小小的,堆满了黑胶唱片和老电影的DVD,都是宋专门去鼓楼的唱片店和三里屯的碟片店给楠买的。
宋为了楠,放弃了自己的梦想,开了一家咖啡店。
有一天,宋和朋友路过街尾,看到他曾经看中的那家店开张了,还是一家足疗店。
宋看了很久。
朋友问他,为了一个妞,你连人生的路都改变了,值不值?
宋想都没想,回答,值。
我们每个人的人生,都会遇到一个,让我们奋不顾身的人。
6、
宋和楠两个人渐渐熟起来。
楠会窝在宋的咖啡厅,两人聊音乐,电影,文学。
宋知道了楠最喜欢的导演是马丁·斯科塞斯,最喜欢的歌手是吉姆·莫里森,最喜欢的文学是《北回归线》。
楠生日前的一个月,宋翻遍了同学录,发动了全部人脉,才找到一个在洛杉矶的幼儿园同学。
宋托他带回来了一张黑色叛逆摩托俱乐部亲笔签名的CD,还有海报。
生日那天,红楠收到礼物,特别高兴,她赖在宋的咖啡厅,坐了很久很久,喝了很多很多酒后,终于对宋歌说,我喜欢上了一个人,最近才确定的心意。
宋感叹,自己整容般的重生终于得到了回报。
宋很克制地对着镜子缕了缕头发,问楠,是谁啊?
楠说,是小北。
7、
饭局上,楠介绍小北给宋认识。
小北梳着一个垄沟辫,胳膊上是一个骷髅纹身。
宋问小北,你知道黑色叛逆摩托俱乐部么?
小北说,黑色叛逆摩托俱乐部?那是什么?
宋一愣,小北不是文艺青年。
宋又问楠,他是做什么的?
楠说,他是街尾足疗店的老板。
宋笑了,小北是个粗人。
但是楠爱上了小北。
宋以为楠不喜欢粗人,所以才努力成为文青。
但他错了,她不是不喜欢粗人,她只是不喜欢他。
这大概是爱情中最绝望的事情了。
爱的人不爱你,不是因为你不是他们喜欢的那款,不是因为你哪里不达标,不是因为你哪里不好。
只是因为,他们不喜欢你。
这样的你,那样的你,好的你,坏的你,用一颗永远火辣的心去爱的你。
都不喜欢。
捂在宋胸口,那颗火辣辣的心,终于凉了,而且凉透了。
8、
大学城街尾有一家足疗店。
店主小北是个粗人,会带女朋友楠去足疗、烫头和蹦迪。
楠很开心。
大学城街头有一家咖啡店。
店主宋,独身,他的店里堆满了黑胶和DVD。
他不再足疗、烫头和蹦迪。
他是真的迷上了电影,音乐,还有文学。
他真的成为了一个文青,沧桑的那种,有双有故事的眼睛,和一颗凉的心。
朋友又问他,为了一个错的人,连人生的路都改变了,值不值?
宋想了很久,没有得出答案。
很久之后的一天,宋坐在咖啡厅听歌发呆。
他不知道,这样的他,已经被一个短发漂亮,骑着机车,胳膊上有纹身的女孩子盯了很久很久。
女孩在喝完第十二杯咖啡之后,起身,大步走到宋歌旁边,问,打扰一下,你在听歌么?
宋点头,问,黑色叛逆摩托俱乐部。你喜欢么?
女孩子笑眯眯的,说,完全不喜欢,只是我有点喜欢你,可不可以占用你听歌的时间,和我去蹦迪?
朋友曾经问宋,为了一个错的人,连人生的路都改变了,值不值?
宋想了很久,终于得到了答案。
我们每个人的人生,都会遇到一个,让我们奋不顾身,让我们破例的人。
我们为他们改变了人生,改变了自己,用火辣辣的心去追求他们。
但结局或许不如人愿。
没关系,这条因爱而曲折改变的路,可能会带我们遇到新的人,让我们明白所有错过都值得。
读懂一朵花,
便也读懂了一个世界……
师父常说,一花一世界,一叶一菩提。读懂了一朵花,也许就读懂了一个世界,读懂了世间万物的苦与乐。
一朵花对于小昆虫来说就是一个世界;小昆虫对于寄生在它身上的微生物来说也是一个世界;而我每个人也自成一个世界。
宏观世界与微观世界,其实没有大小之分。在每个世界里,都有万物,万物也都有自己的欢乐与痛苦。而我们作为宏观世界中的小小一份子,就如同星辰大海里的一粒小尘埃,痛苦也就显得那么的微不足道了。
一花而见春,一叶而知秋。寻常细微之物,常是大千世界的缩影,无限往往珍藏于有限之中。当你有了随时将微观世界与宏观世界转换的眼界时,你就会想开很多事情,痛苦也会随之消弭。
参透这些,大千世界都能了然于胸。这时的你,就能真正做到心若无物了。
欢迎使用WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!