判断节点Not Ready时效设置
k8s默认节点not ready需要经过40s时间,可以通过以下参数进行修改
vim /etc/kubernetes/manifest/kuber-controller-manager.yaml
--node-monitor-grace-period=20s
vim /var/lib/kubelet/kubeadm-flags.env
--node-status-update-frequency=4s
vim /etc/kubernetes/manifest/kuber-controller-manager.yaml
--node-monitor-grace-period=20s
vim /var/lib/kubelet/kubeadm-flags.env
--node-status-update-frequency=4s
备注:
--node-status-update-frequency 指定kubelet的上报频率
--node-monitor-grace-period 失联指定时间后,将节点状态readey变成为not ready
--node-monitor-grace-period需要是--node-status-update-frequency整数倍
社区默认的配置
--node-status-update-frequency 10s --node-monitor-period 5s --node-monitor-grace-period 40s
快速更新和快速响应
--node-status-update-frequency 4s --node-monitor-period 2s --node-monitor-grace-period 20s
节点Not Ready之后 pod驱逐并重启时效设置
节点Not Ready 之后, k8s默认需要300s时间,在新的节点上启动重新启动Pod, 可以通过以下参数修改。
设置以下参数
vim /etc/kubernetes/manifest/kube-apiserver.yaml
- --default-not-ready-toleration-seconds=10 - --default-unreachable-toleration-seconds=10
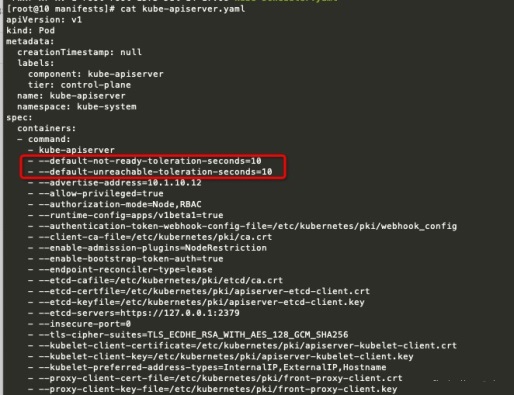
设置之后pod会被自动加上以下容忍污点
tolerations: - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 10 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 10
故障隔离时效
节点故障隔离由node-agent和节点隔离controller控制器组成,检测kubelet,docker,containerd,calico等组件是否异常,隔离机制如下图所示:

Node-Agent上报的心跳时间间隔1s,连续5次为失败,即5s触发隔离, 为节点设置NoExecute污点,立即驱逐故障节点上的pod,k8s自动调度到其他正常的节点运行pod。